I finally moved to Github pages!
Check out my new content so far:
Sunday, January 4, 2015
Wednesday, March 26, 2014
Clojure HashMap usage within a Java class
I attended the Hack (Make!) the Bank hackathon that took place on Level 39 (One Canada Square in London). My team decided to make a funds reallocating application that makes automatic payments once an account is topped up. Long story short, we got stuck at interoperability with the Java classes providing Paypal access.
We made the mistake of inserting a Clojure hash map directly to the Java class, which seemed to work but the moment we switched to paper account in the Java class (by modifying the incoming HashMap argument) the system threw an exeption. Ben from Erudine Financial realized that the structure we were passing was inmutable so we just created the proper Java HashMap instance.
This situation happens especially when clumsily using proof of concept code in production.
We made the mistake of inserting a Clojure hash map directly to the Java class, which seemed to work but the moment we switched to paper account in the Java class (by modifying the incoming HashMap argument) the system threw an exeption. Ben from Erudine Financial realized that the structure we were passing was inmutable so we just created the proper Java HashMap instance.
(java.util.HashMap. {})Remember that Clojure's {} is actually a clojure.core.PersistentHashMap.
This situation happens especially when clumsily using proof of concept code in production.
Sunday, March 2, 2014
The Gaussian kernel maps data onto the sphere
It is a fact as surprising as trivial that the Gaussian kernel maps your data onto the infinite-dimensional sphere. No computation regarding the RKHS basis are required, since, given the kernel
$$k(x,y)=\exp(-\gamma \| x-y\|^2)$$
defined on the domain $X$, inducing a map $\Phi: X \rightarrow F$, where $F$ is the associated feature space.
We have that $k(x,x)=1$ for all $x \in X$. Therefore what we have is clearly the sphere, since all $x$ are one unit await from zero in the feature space $\|\Phi(x)\|^2 = \sum_i \lambda_i \phi_i(x) \phi_i(x) = k(x,x)=1$. Is there any possible refinement to this? There is! Remember that the Fourier transform of a Gaussian is a Gaussian (with inverted paramers, etc), so we have that the Fourier coefficient 0 (i.e., the power of the constant function, or $cos(0)$) is positive (and maximum among the coefficients). This means that all data have a positive first entry (the constant function is positive and its coefficient is positive), which means that the map actually is from the domain to the positive halve of the infinite hypersphere. Other basis functions (for coefficients other that zero) are sines and cosines and thus may change points. Further characteristics of the mapping depend on the data probability measure.
If you have been trying to apply Differential Geometry to kernel methods and have worked with the Gaussian without noticing it, please stop your research and do something else. A good review and analysis on the induced manifold is Geodesic Analysis on the Gaussian RKHS hypersphere, where the authors make again the same mistake many people do: Naming the feature space as the RKHS (IT IS ITS DUAAAAALLLLLL). In fact, they show that the maximum angle between a pair of points is $\pi/2$, which makes the largest possible embedding a quadrant.
$$k(x,y)=\exp(-\gamma \| x-y\|^2)$$
defined on the domain $X$, inducing a map $\Phi: X \rightarrow F$, where $F$ is the associated feature space.
We have that $k(x,x)=1$ for all $x \in X$. Therefore what we have is clearly the sphere, since all $x$ are one unit await from zero in the feature space $\|\Phi(x)\|^2 = \sum_i \lambda_i \phi_i(x) \phi_i(x) = k(x,x)=1$. Is there any possible refinement to this? There is! Remember that the Fourier transform of a Gaussian is a Gaussian (with inverted paramers, etc), so we have that the Fourier coefficient 0 (i.e., the power of the constant function, or $cos(0)$) is positive (and maximum among the coefficients). This means that all data have a positive first entry (the constant function is positive and its coefficient is positive), which means that the map actually is from the domain to the positive halve of the infinite hypersphere. Other basis functions (for coefficients other that zero) are sines and cosines and thus may change points. Further characteristics of the mapping depend on the data probability measure.
If you have been trying to apply Differential Geometry to kernel methods and have worked with the Gaussian without noticing it, please stop your research and do something else. A good review and analysis on the induced manifold is Geodesic Analysis on the Gaussian RKHS hypersphere, where the authors make again the same mistake many people do: Naming the feature space as the RKHS (IT IS ITS DUAAAAALLLLLL). In fact, they show that the maximum angle between a pair of points is $\pi/2$, which makes the largest possible embedding a quadrant.
Wednesday, February 26, 2014
On the computer languages market
There is an interesting series of articles on Dr. Dobb's essentially about what we can call the computer languages market, where they analyze trends and caracteristics, especially in the Editor in chief's article.
They analyze the trends in language usage, which ordinally had not change since the year before (C, Java, Objective-C, C++, C#, PHP, Visual Basic, Python and Javascript), but that show a number of developments. For instance, Perl is leaving room in favor of Python. Perl seems to be dying and with signs of becoming history. They also mentioned a strong resurgence of Javascript but I would like to add that a large number of developments in the web scripting world have been carried out, starting with CoffeeScript, a tiny language that translates 1-to-1 to JavaScript. See their web page for some use of the language. ClojureScript is another compiler, this time to translate Clojure into JavaScript.
I found the following paragraph of particular interest:
An interesting development they had not talked about in the area of systems programming, more than the D language, is Nimrod. It has cool features such as pointers that are traced by a lightweight garbage collector and others that directly translate to C++ pointers. Templates that can be called as operators are included, supporting metaprogramming, it supports inmutable objects, a number of syntactic sugars (such as being able to call len(x), x.len or x.len if there is only one argument, command and function-like calls like echo("hello") and echo "hello"...), first class functions and a very good mixture between Python indentation-defined blocks and Scala function definitions, as opposed to D's C-like syntax. Nimrod compiles to C, C++, Objective C and JavaScript. Definitely a good candidate to learn and to watch.
On the functional but high-performant side of the market we have Erlang, Haskell, Scala and Clojure. The first three are older, especially the first two ones. In my opinion, Clojure is simplest, especially when compared to Scala. This is patent when examining a source coude listing in both languages. Clojure lifts the programmer's productivity to new highs (I was able to code the Denarius' matching engine core in half a day). Definitely the way to go in the future.
They analyze the trends in language usage, which ordinally had not change since the year before (C, Java, Objective-C, C++, C#, PHP, Visual Basic, Python and Javascript), but that show a number of developments. For instance, Perl is leaving room in favor of Python. Perl seems to be dying and with signs of becoming history. They also mentioned a strong resurgence of Javascript but I would like to add that a large number of developments in the web scripting world have been carried out, starting with CoffeeScript, a tiny language that translates 1-to-1 to JavaScript. See their web page for some use of the language. ClojureScript is another compiler, this time to translate Clojure into JavaScript.
I found the following paragraph of particular interest:
By all measures, C++ use declined last year, demonstrating that C++11 was not enough to reanimate the language's fortunes, despite the significant benefits it provides. I have previously opined that Microsoft's contention of a return to native languages being led by C++ was unsupported by evidence. It is now clearly contradicted by the evidence.I feel encouraged by this statement. I believed C++ is an awful language, and always has been. Back in the late 90's when I started programming and my teenage budget in a remote outpost included a non-disposable 486 DX2 with DOS, we had no choice but to get mainstream technical stuff, and that included C++ as the only advanced systems language. My experience, and I believe everybody's experience, is that programmer's time is more important than running time, and even hardcore C++ programmers recognize they put themselves in pain when facing non-standard tasks with the language. Some would argue that pain is what you pay for system performance, but that is not true (see the paragraph below). C++ will never grow on Big Data (data processing), mobile development or cloud computing, and I would expect that performance computing to also cut C++ usage in favor of more modern, maintainable system languages, such as the D language (or the one I describe below).
An interesting development they had not talked about in the area of systems programming, more than the D language, is Nimrod. It has cool features such as pointers that are traced by a lightweight garbage collector and others that directly translate to C++ pointers. Templates that can be called as operators are included, supporting metaprogramming, it supports inmutable objects, a number of syntactic sugars (such as being able to call len(x), x.len or x.len if there is only one argument, command and function-like calls like echo("hello") and echo "hello"...), first class functions and a very good mixture between Python indentation-defined blocks and Scala function definitions, as opposed to D's C-like syntax. Nimrod compiles to C, C++, Objective C and JavaScript. Definitely a good candidate to learn and to watch.
On the functional but high-performant side of the market we have Erlang, Haskell, Scala and Clojure. The first three are older, especially the first two ones. In my opinion, Clojure is simplest, especially when compared to Scala. This is patent when examining a source coude listing in both languages. Clojure lifts the programmer's productivity to new highs (I was able to code the Denarius' matching engine core in half a day). Definitely the way to go in the future.
Monday, February 10, 2014
Machine learning in a few words
Machine learning is becoming a buzzword, everybody talks aboit it and few seem to be interested in the math underneath (I find statements like "I wanted to know more but all sources were too statistical/mathematical and I wanted more practical stuff").
Let me tell you something:
First: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Second: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Third: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Machine Learning is just a fancy word for the statistical/mathematical tools lying underneath, whose objective is to extract something that we may loosely call knowledge (or something that we understand) from data (or something chaotic that we do not understand), so that computers may take action based on the inferred knowledge. An example of this would be a robot arm/humanoid: without programming actions on direction/velocity/acceleration vectors based on an established model, we may put sensonrs on a subject's articulations, and from these datapoints learn a regression model on the manifold of natural movements. Another example is in Business Intelligente: We may learn groups of customers (market segmentation) so that we may engage several groups with specific policies or offers target at them.
Maching Learning is applied Statistics/Mathematics. Is very little and very unpractical without Optimization/Operations Research, from the algorithmic and practical/scalable point of view.
I've come to the conclusion that there exists two large main approaches to ML, disregarding the specific technique we are dealing with and its target (i.e., supervised or unsupervised), plus one in the middleway:
Reinforment learning is nowadays just a fancy word for techniques widely known, studied and used in Stochastic Processes, HMM (Hidden Markov Models) being the only exception. Sometimes they call it Sequential Learning, but it is not widely considered Machine Learning, neither scholarly nor popularly.
So, as you can see, there is nothing new (not at least as the discovery of the fundamental theorem of calculus, or of quantum mechanics).
Regarding novelty, I am annoyed each time I read about ML techniques from the big data guys, who are normally programmers starting to do something more that data aggregation and querying. It seems that there is something both new and exotic in what they are saying, and it it mostly well known techniques from statistics, such as this article, or the beginning of Sean Owen's presentation at Big Data Spain.
Now, the practical side of things require that ML scales to Big Data. That limits the applicability of matrices and non-linear transformations to adapt linear methods, so let's see what the next breakthrough is.
Let me tell you something:
First: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Second: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Third: You can't really use Machine Learning if you don't know the statistical/mathematical basis
Machine Learning is just a fancy word for the statistical/mathematical tools lying underneath, whose objective is to extract something that we may loosely call knowledge (or something that we understand) from data (or something chaotic that we do not understand), so that computers may take action based on the inferred knowledge. An example of this would be a robot arm/humanoid: without programming actions on direction/velocity/acceleration vectors based on an established model, we may put sensonrs on a subject's articulations, and from these datapoints learn a regression model on the manifold of natural movements. Another example is in Business Intelligente: We may learn groups of customers (market segmentation) so that we may engage several groups with specific policies or offers target at them.
Maching Learning is applied Statistics/Mathematics. Is very little and very unpractical without Optimization/Operations Research, from the algorithmic and practical/scalable point of view.
I've come to the conclusion that there exists two large main approaches to ML, disregarding the specific technique we are dealing with and its target (i.e., supervised or unsupervised), plus one in the middleway:
- Functional approach (Mathematical)
- Neural Network/Deep Learning approach (Middle way)
- Probabilistic approach (Statistical)
I have my data set and a buch of (linear or non-linear) transformations, find a solution applying these transformations to my data so that I can maximize a score functional that I like for my problem. If I want to predict something (classification/regression) then combine these transformations so that the combination fits best my target variable. If I want to examine the nature of the data (dimensionality reduction, matrix factorization, clustering), then use a combination of my transformations to lose as least information as possible (measured with a functional, again).In the probabilistic approach, the prior knowledge is an assupmtion of the prior probability and the likelyhood, and works towards obtaining a posterior probability (that the outcome is a given choice given the data just seen). Examples are: Logistic Regression (simple non-linear transformation for classification), Naive Bayes (classification), SNE, Gaussian Processes... The general idea is
I want to see independence at the end of the process, therefore I can assume Gaussian multivariate variables so that a linear or non-linear transformation gives me components that are as independent as possible (for unsupervised learning) or assume a probability distribution at the output and a likelyhood and compute a model so that I best fit the likelihood of seeing the target variable given the data.Neural networks and deep learning are a different story. I consider them to be their own field, drawing tools from the above. They are neither functional because they are not dealing directly with functions (transformations) in the functional analytic setting, and they are not probabilistic for obvious reasons, but use any probability or information theoretic tool as needed. The fact that they connect output of transformations to inputs makes this field related to the first approach indeed, seen as a chain of transformations (spaces defined on the image of their predecessors), but the focus here is obviously the algorithms and that changes things.
Reinforment learning is nowadays just a fancy word for techniques widely known, studied and used in Stochastic Processes, HMM (Hidden Markov Models) being the only exception. Sometimes they call it Sequential Learning, but it is not widely considered Machine Learning, neither scholarly nor popularly.
So, as you can see, there is nothing new (not at least as the discovery of the fundamental theorem of calculus, or of quantum mechanics).
Regarding novelty, I am annoyed each time I read about ML techniques from the big data guys, who are normally programmers starting to do something more that data aggregation and querying. It seems that there is something both new and exotic in what they are saying, and it it mostly well known techniques from statistics, such as this article, or the beginning of Sean Owen's presentation at Big Data Spain.
Now, the practical side of things require that ML scales to Big Data. That limits the applicability of matrices and non-linear transformations to adapt linear methods, so let's see what the next breakthrough is.
Saturday, February 8, 2014
Use Java JARs within Clojure projects
I am creating a clojure wrapper for the excellent library from Pekka Enberg Falcon, which will provide Denarius with FIX protocol communication capabilities. The new project's name is, obviously, falcon-clj.
Although the ideal packaging would be to include Falcon as a Git submodule, I decided to pre-compile Denarius into a JAR stored into the /lib directory to avoid Leiningen complications in the starting phase and be able to focus on the implementation.
I compiled the library and pushed it into Github and then I received my new laptop, so I installed everything from scratch, including the JDK, and cloned everything back into the new laptop. The next stage would be to use the REPL to quickly get used to Falcon.
Basically, you need to explicitly tell Eclipse to use the external JDK you are using. You can find the setting under Window -> Preferences -> Java -> Installed JREs.
Although the ideal packaging would be to include Falcon as a Git submodule, I decided to pre-compile Denarius into a JAR stored into the /lib directory to avoid Leiningen complications in the starting phase and be able to focus on the implementation.
I compiled the library and pushed it into Github and then I received my new laptop, so I installed everything from scratch, including the JDK, and cloned everything back into the new laptop. The next stage would be to use the REPL to quickly get used to Falcon.
=> (import [falcon.fix Session Versions])So I digged up a little bit and found some interesting information here, which led me to here and then to correctly configure Eclipse (Aptana) to use an external JRE to run things.
UnsupportedClassVersionError falcon/fix/Session : Unsupported major.minor version 51.0 java.lang.ClassLoader.defineClass1 (:-2)
Basically, you need to explicitly tell Eclipse to use the external JDK you are using. You can find the setting under Window -> Preferences -> Java -> Installed JREs.
Saturday, February 1, 2014
What lies underneath malloc
malloc is C's dynamic memory allocation function: memory is assigned to the process heap and then the malloc dynamic assignation does its magic, to make boundaries between dynamically assigned variables. Here's how it works (bear in mind that a malloc implementation is largely compiler-dependent):
At the beginning of the process' heap free space, a special region is allocated to point to the next available byte address in the free region and a previous pointer to the pointers corresponding to the previously allocated block. In case there is no block allocated next, the pointer is null. Otherwise, the pointer will point as many bytes ahead in the process memory as the corresponding allocated block's size.
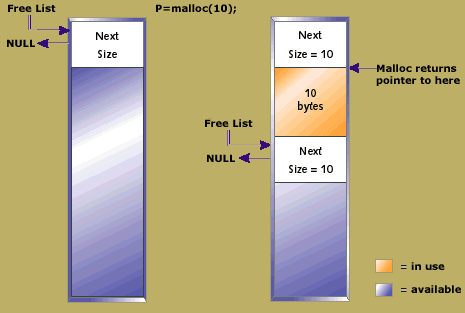
The function free updates the following block's previous pointer after the recently liberated block, which causes mismatch with the preceding block's next pointer pointing to the deleted block. This creates an accounted free block. To speed up, free can have its own list of free block and sizes elsewhere on the heap.
At the beginning of the process' heap free space, a special region is allocated to point to the next available byte address in the free region and a previous pointer to the pointers corresponding to the previously allocated block. In case there is no block allocated next, the pointer is null. Otherwise, the pointer will point as many bytes ahead in the process memory as the corresponding allocated block's size.
The function free updates the following block's previous pointer after the recently liberated block, which causes mismatch with the preceding block's next pointer pointing to the deleted block. This creates an accounted free block. To speed up, free can have its own list of free block and sizes elsewhere on the heap.
Subscribe to:
Posts (Atom)